Race Conditions in Cloud Security Posture Management
Race conditions - the archenemy of all detective and corrective controls.
Cloud Security Posture Management (CSPM) a well established market with a market cap north of US$ 4 billion, including large SaaS products like Prisma and Wiz to open source solutions like Cloud Custodian.
Most enterprises with a cloud presence will have some form of a CSPM.
I'm using CSPM as an example. There's a lot of nuance in the market today, with tooling focusing on assets, relationships, remediations, workload coverage, etc. The principle applies to Cloud Workload Protection Platform (CWPP), or any other tech that works on the same basis.
If you're on AWS for example, your CSPM will either try to call Describe* every so often and potentially combine this with a CloudTrail event.
The idea is that if preventive controls aren't possible, the CSPM will detect and even remediate or at least report the security event. According to the SANS cloud security survey, misconfigurations of cloud services played a part in ~42% of all attacks. And through the power of the cloud we can automatically remediate these misconfigurations.
In AWS preventive controls, those described in the data perimeter for example, are relatively new. Restructuring your organisation with a data perimeter in mind requires a significant effort. You'll need to rebuild and rethink about foundational services. Which is why I believe CSPMs will continue to thrive and continue to fill a gap in the market.
The fist problem with detective and corrective controls is that they are bound to TOCTOU race conditions. The time that it takes for an event to be published in an audit log (detected) and then corrected, is enough for an adversary to exploit the misconfiguration. In reality this is due to delivery time gaps, for example CloudTrail delivers an event within 5 minutes of the API call.
In reality it's ~5 seconds, which is plenty of time to exploit a detective/corrective control combo. I'm picking CloudTrail as an example, other Cloud Service Providers (CSP) are on the same level more or less.
The second problem with CSP's APIs is that they fail all the time. Because that's how computers work. It could be throttling, it could be elevated error rates, a self-inflicted recursive loop, or an attacker DoSing your quota so that the CSPM won't be able to query your account. The outcome is the same. Your CSPM fails to get an accurate view of a resource. That Describe* call fails. The attacker can create a window of opportunity to elude the detection of your tooling. Your CSPM doesn't have a special partner's API. We all use the same APIs.
In other words you shouldn't lean exclusively on the capabilities of detective and corrective controls, despite their allure of automation.
Self-healing is great, preventing is better, understanding all failure modes is the best.
Here's a typical scenario:
Application teams in your organisation have the power to manage their network with guardrails. App teams can create VPCs without public subnets and use PrivateLink. The most common service they reach out is S3, and they create an S3 VPC gateway endpoint, and modify its policy to reach their buckets.
The threat we're trying to mitigate here is that an attacker inside the VPC - with app team privileges - can reach out to any bucket via this VPC endpoint. You can use aws:PrincipalAccount, to stop the attacker from bringing their own credentials, but that's about it. You can treat this as a non-malicious misconfiguration as well, but we'll stick with our attacker persona.
You can't use an SCP on all identities like aws:ResourceAccount and co. because there are legitimate usecases for reaching out to S3 buckets that sit outside your AWS org. For example arn:aws:s3:::repo.*.amazonaws.com used for building your Amazon Linux 2 golden AMIs.
You decide to lean against your CSPM. You have an allowlist of buckets and when an app team creates an VPC Endpoint the CSPM detects the event, checks the endpoint policy, and provides a corrective action by applying a stricter endpoint policy.
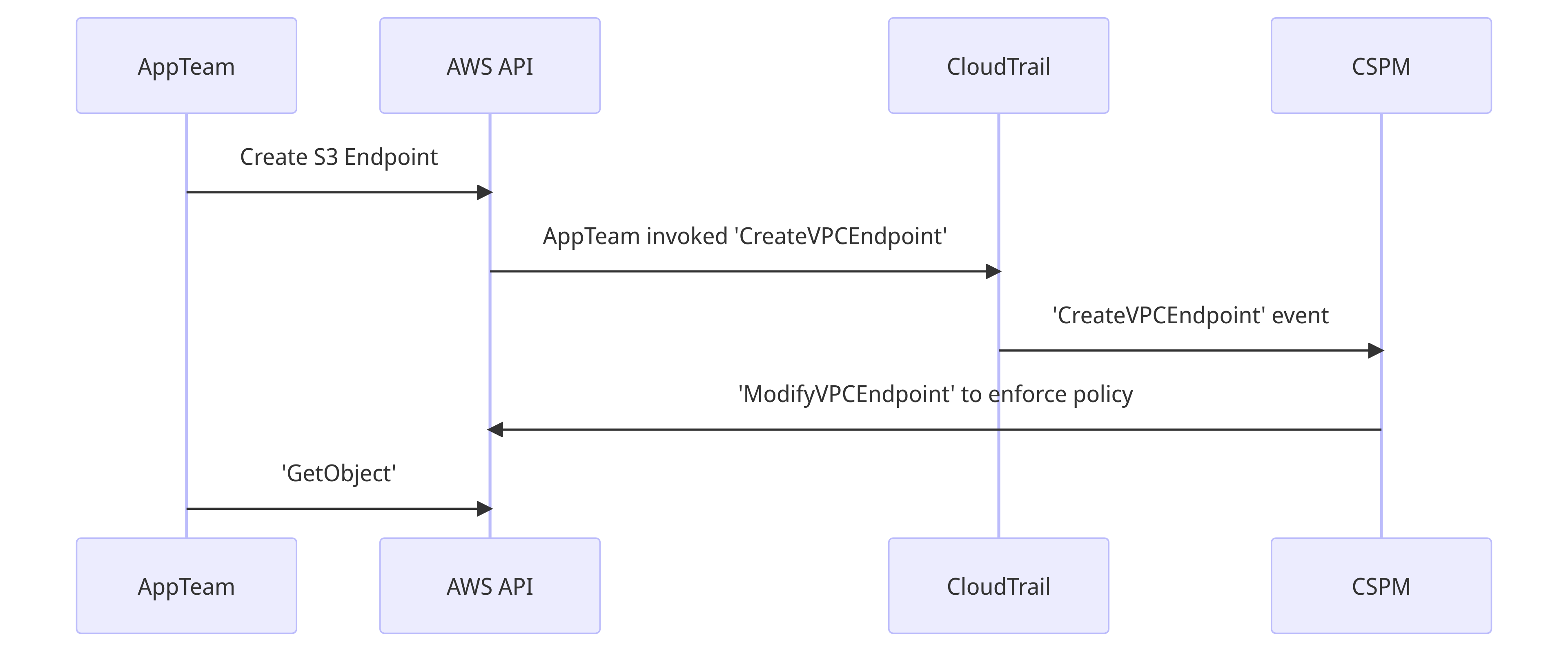
The app team creates an S3 endpoint, CSPM picks up the event from CloudTrail, and applies the default restricted policy. When they try to GetObject the VPC endpoint applied by the CSPM enforces the bucket allowlist.
This is the happy path for the CSPM. The remediation action takes place before the "exfiltration" event. However, typically CloudTrail delivers an event within 5 minutes of the API call.
The race condition is on the last two steps. If the attacker manages to GetObject before the restrictive policy is applied - and sometimes they get 5 minutes - they could establish a connection to their S3 bucket.
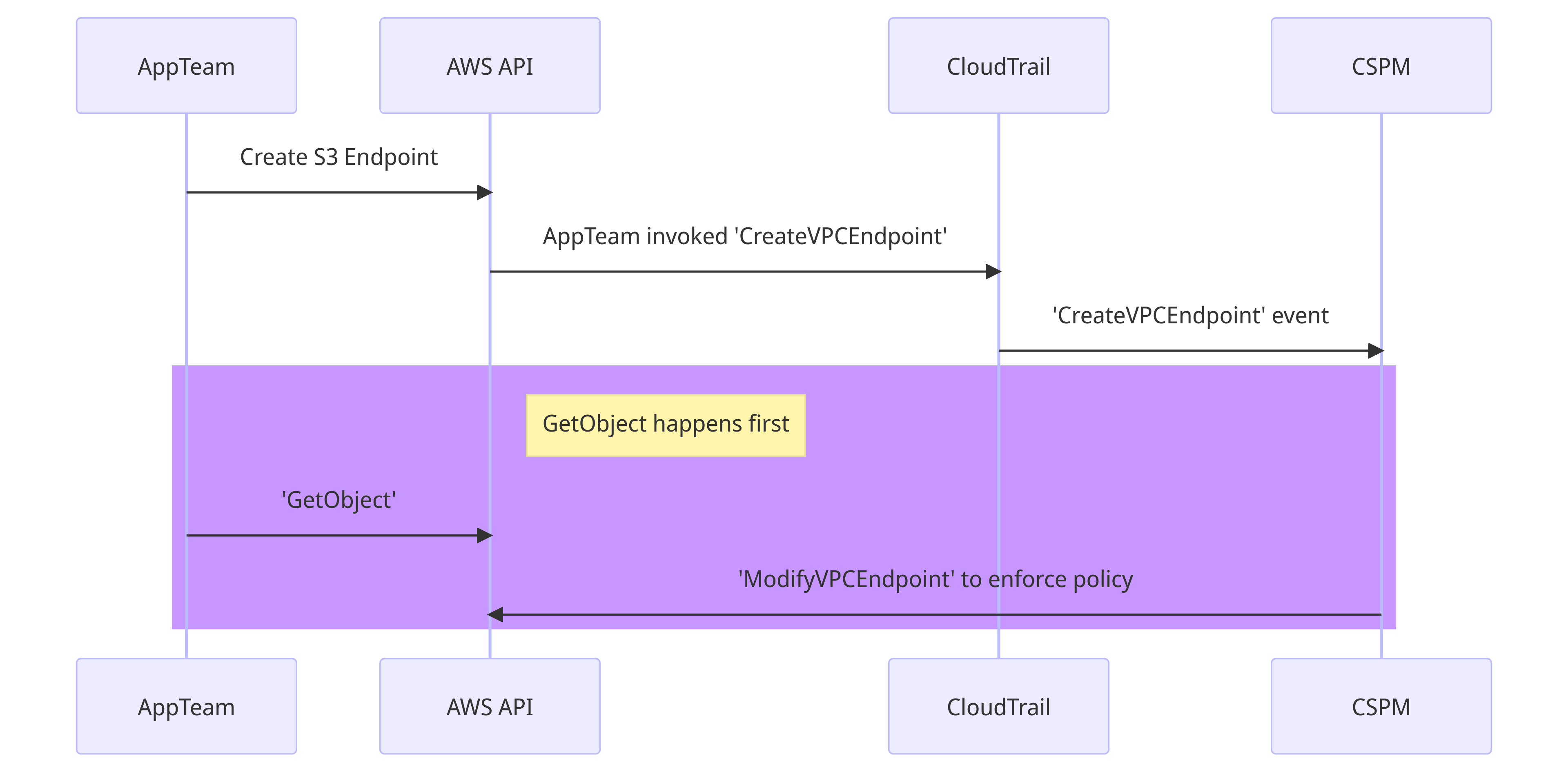
Once a connection has been authenticated and authorised via the endpoint, the policy change on the endpoint will not reset the connection. You might be thinking, "the attacker needs to recreate the endpoint until they win the race condition" and that's slow and noisy. Unless the app team can also ModifyVPCEndpoint, in which case the attack becomes trivial.
Here's what the happy path for the attacker looks like in that case.
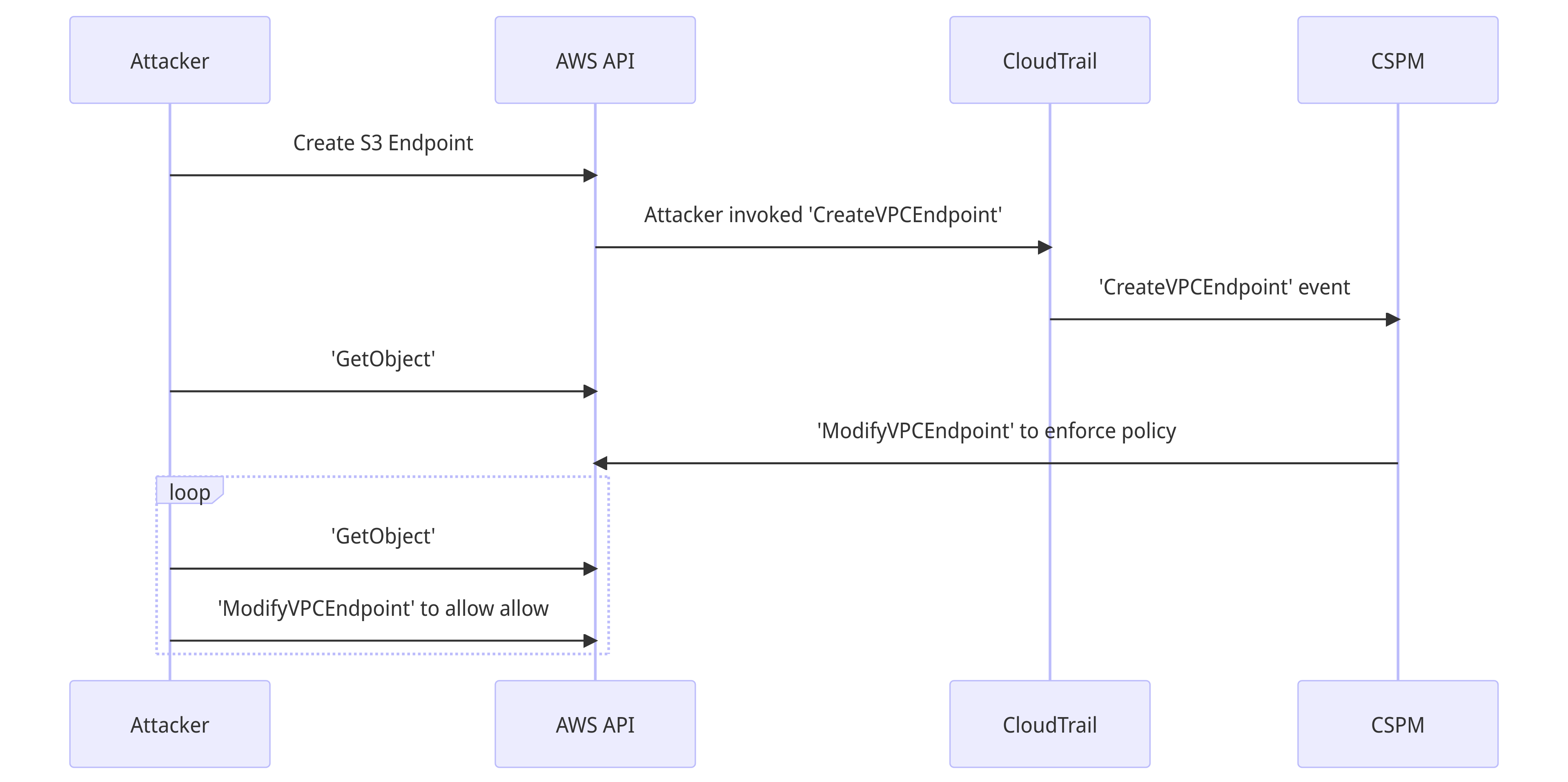
It's noisy, and it will be detected after the fact with frequency analysis - if you do this sort of thing - on the CloudTrail events.
For our scenario - bar any preventive controls on the IAM Identities - that would be as good as it gets.
Examples where this type of race condition is applicable in AWS:
- All services with resource policies
- All VPC Endpoints with policies
- VPC Endpoint connections to external endpoint services and vice versa
- Role policy attachment enforcement
Next time you revisit your controls and remediation strategy, review if you should follow a different strategy altogether.
You can read part 2 for follow up practical example.